| Technical Level: | Expert | Published: | |
|---|
| Author: | Markus Sobek | Last Updated: | - |
|---|
Introduction
This article includes the following sections.
Introduction
Within the past few years, Google has become the far most utilized search engine worldwide. A decisive factor therefore was, besides high performance and ease of use, the superior quality of search results compared to other search engines. This quality of search results is substantially based on PageRank, a sophisticated method to rank web documents.
The aim of these pages is to provide a broad survey of all aspects of PageRank. The contents of these pages primarily rest upon papers by Google founders Lawrence Page and Sergey Brin from their time as graduate students at Stanford University.
MIS Editor: Thanks to pr.efactory.de and Markus Sobek for allowing us to reproduce this article. PageRank and Google are trademarks of Google Inc., Mountain View CA, USA. PageRank is protected by US Patent 6,285,999. Copyright for this article belongs to pr.efactory.de.
It is often argued that, especially considering the dynamic of the internet, too much time has passed since the scientific work on PageRank, as that it still could be the basis for the ranking methods of the Google search engine. There is no doubt that within the past years most likely many changes, adjustments and modifications regarding the ranking methods of Google have taken place, but PageRank was absolutely crucial for Google's success, so that at least the fundamental concept behind PageRank should still be constitutive.
The PageRank Concept
Since the early stages of the world wide web, search engines have developed different methods to rank web pages. Until today, the occurence of a search phrase within a document is one major factor within ranking techniques of virtually any search engine. The occurence of a search phrase can thereby be weighted by the length of a document (ranking by keyword density) or by its accentuation within a document by HTML tags.
For the purpose of better search results and especially to make search engines resistant against automatically generated web pages based upon the analysis of content specific ranking criteria (doorway pages), the concept of link popularity was developed. Following this concept, the number of inbound links for a document measures its general importance. Hence, a web page is generally more important, if many other web pages link to it. The concept of link popularity often avoids good rankings for pages which are only created to deceive search engines and which don't have any significance within the web, but numerous webmasters elude it by creating masses of inbound links for doorway pages from just as insignificant other web pages.
Contrary to the concept of link popularity, PageRank is not simply based upon the total number of inbound links. The basic approach of PageRank is that a document is in fact considered the more important the more other documents link to it, but those inbound links do not count equally. First of all, a document ranks high in terms of PageRank, if other high ranking documents link to it.
So, within the PageRank concept, the rank of a document is given by the rank of those documents which link to it. Their rank again is given by the rank of documents which link to them. Hence, the PageRank of a document is always determined recursively by the PageRank of other documents. Since - even if marginal and via many links - the rank of any document influences the rank of any other, PageRank is, in the end, based on the linking structure of the whole web. Although this approach seems to be very broad and complex, Page and Brin were able to put it into practice by a relatively trivial algorithm.
The original PageRank algorithm was described by Lawrence Page and Sergey Brin in several publications. It is given by:
PR(A) = (1-d) + d (PR(T1)/C(T1) + ... + PR(Tn)/C(Tn))
where:
- PR(A) is the PageRank of page A,
- PR(Ti) is the PageRank of pages Ti which link to page A,
- C(Ti) is the number of outbound links on page Ti and
- d is a damping factor which can be set between 0 and 1.
So, first of all, we see that PageRank does not rank web sites as a whole, but is determined for each page individually. Further, the PageRank of page A is recursively defined by the PageRanks of those pages which link to page A.
The PageRank of pages Ti which link to page A does not influence the PageRank of page A uniformly. Within the PageRank algorithm, the PageRank of a page T is always weighted by the number of outbound links C(T) on page T. This means that the more outbound links a page T has, the less will page A benefit from a link to it on page T.
The weighted PageRank of pages Ti is then added up. The outcome of this is that an additional inbound link for page A will always increase page A's PageRank.
Finally, the sum of the weighted PageRanks of all pages Ti is multiplied with a damping factor d which can be set between 0 and 1. Thereby, the extend of PageRank benefit for a page by another page linking to it is reduced.
The Random Surfer Model
In their publications, Lawrence Page and Sergey Brin give a very simple intuitive justification for the PageRank algorithm. They consider PageRank as a model of user behaviour, where a surfer clicks on links at random with no regard towards content.
The random surfer visits a web page with a certain probability which derives from the page's PageRank. The probability that the random surfer clicks on one link is solely given by the number of links on that page. This is why one page's PageRank is not completely passed on to a page it links to, but is devided by the number of links on the page.
So, the probability for the random surfer reaching one page is the sum of probabilities for the random surfer following links to this page. Now, this probability is reduced by the damping factor d. The justification within the Random Surfer Model, therefore, is that the surfer does not click on an infinite number of links, but gets bored sometimes and jumps to another page at random.
The probability for the random surfer not stopping to click on links is given by the damping factor d, which is, depending on the degree of probability therefore, set between 0 and 1. The higher d is, the more likely will the random surfer keep clicking links. Since the surfer jumps to another page at random after he stopped clicking links, the probability therefore is implemented as a constant (1-d) into the algorithm. Regardless of inbound links, the probability for the random surfer jumping to a page is always (1-d), so a page has always a minimum PageRank.
A Different Notation of the PageRank Algorithm
Lawrence Page and Sergey Brin have published two different versions of their PageRank algorithm in different papers. In the second version of the algorithm, the PageRank of page A is given as:
PR(A) = (1-d) / N + d (PR(T1)/C(T1) + ... + PR(Tn)/C(Tn))
where N is the total number of all pages on the web. The second version of the algorithm, indeed, does not differ fundamentally from the first one. Regarding the Random Surfer Model, the second version's PageRank of a page is the actual probability for a surfer reaching that page after clicking on many links. The PageRanks then form a probability distribution over web pages, so the sum of all pages' PageRanks will be one.
Contrary, in the first version of the algorithm the probability for the random surfer reaching a page is weighted by the total number of web pages. So, in this version PageRank is an expected value for the random surfer visiting a page, when he restarts this procedure as often as the web has pages. If the web had 100 pages and a page had a PageRank value of 2, the random surfer would reach that page in an average twice if he restarts 100 times.
As mentioned above, the two versions of the algorithm do not differ fundamentally from each other. A PageRank which has been calculated by using the second version of the algorithm has to be multiplied by the total number of web pages to get the according PageRank that would have been caculated by using the first version. Even Page and Brin mixed up the two algorithm versions in their most popular paper "The Anatomy of a Large-Scale Hypertextual Web Search Engine", where they claim the first version of the algorithm to form a probability distribution over web pages with the sum of all pages' PageRanks being one.
In the following, we will use the first version of the algorithm. The reason is that PageRank calculations by means of this algorithm are easier to compute, because we can disregard the total number of web pages.
The Characteristics of PageRank
The characteristics of PageRank shall be illustrated by a small example.
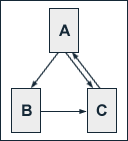
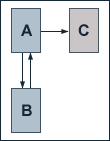
We regard a small web consisting of three pages A, B and C, whereby page A links to the pages B and C, page B links to page C and page C links to page A. According to Page and Brin, the damping factor d is usually set to 0.85, but to keep the calculation simple we set it to 0.5. The exact value of the damping factor d admittedly has effects on PageRank, but it does not influence the fundamental principles of PageRank. So, we get the following equations for the PageRank calculation:
PR(A) = 0.5 + 0.5 PR(C)
PR(B) = 0.5 + 0.5 (PR(A) / 2)
PR(C) = 0.5 + 0.5 (PR(A) / 2 + PR(B))
These equations can easily be solved. We get the following PageRank values for the single pages:
PR(A) = 14/13 = 1.07692308
PR(B) = 10/13 = 0.76923077
PR(C) = 15/13 = 1.15384615
It is obvious that the sum of all pages' PageRanks is 3 and thus equals the total number of web pages. As shown above this is not a specific result for our simple example.
For our simple three-page example it is easy to solve the according equation system to determine PageRank values. In practice, the web consists of billions of documents and it is not possible to find a solution by inspection.
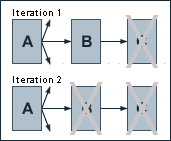
The Iterative Computation of PageRank
Because of the size of the actual web, the Google search engine uses an approximative, iterative computation of PageRank values. This means that each page is assigned an initial starting value and the PageRanks of all pages are then calculated in several computation circles based on the equations determined by the PageRank algorithm. The iterative calculation shall again be illustrated by our three-page example, whereby each page is assigned a starting PageRank value of 1.
| Iteration | PR(A) | PR(B) | PR(C) |
|---|
| 0 | 1 | 1 | 1 |
| 1 | 1 | 0.75 | 1.125 |
| 2 | 1.0625 | 0.765625 | 1.1484375 |
| 3 | 1.07421875 | 0.76855469 | 1.15283203 |
| 4 | 1.07641602 | 0.76910400 | 1.15365601 |
| 5 | 1.07682800 | 0.76920700 | 1.15381050 |
| 6 | 1.07690525 | 0.76922631 | 1.15383947 |
| 7 | 1.07691973 | 0.76922993 | 1.15384490 |
| 8 | 1.07692245 | 0.76923061 | 1.15384592 |
| 9 | 1.07692296 | 0.76923074 | 1.15384611 |
| 10 | 1.07692305 | 0.76923076 | 1.15384615 |
| 11 | 1.07692307 | 0.76923077 | 1.15384615 |
| 12 | 1.07692308 | 0.76923077 | 1.15384615 |
We see that we get a good approximation of the real PageRank values after only a few iterations. According to publications of Lawrence Page and Sergey Brin, about 100 iterations are necessary to get a good approximation of the PageRank values of the whole web.
Also, by means of the iterative calculation, the sum of all pages' PageRanks still converges to the total number of web pages. So the average PageRank of a web page is 1. The minimum PageRank of a page is given by (1-d). Therefore, there is a maximum PageRank for a page which is given by dN+(1-d), where N is total number of web pages. This maximum can theoretically occur, if all web pages solely link to one page, and this page also solely links to itself.
Regarding the implementation of PageRank, first of all, it is important how PageRank is integrated into the general ranking of web pages by the Google search engine. The proceedings have been described by Lawrencec Page and Sergey Brin in several publications. Initially, the ranking of web pages by the Google search engine was determined by three factors:
- Page specific factors
- Anchor text of inbound links
- PageRank
Page specific factors are, besides the body text, for instance the content of the title tag or the URL of the document. It is more than likely that since the publications of Page and Brin more factors have joined the ranking methods of the Google search engine. But this shall not be of interest here.
In order to provide search results, Google computes an IR score out of page specific factors and the anchor text of inbound links of a page, which is weighted by position and accentuation of the search term within the document. This way the relevance of a document for a query is determined. The IR-score is then combined with PageRank as an indicator for the general importance of the page. To combine the IR score with PageRank the two values are multiplicated. It is obvious that they cannot be added, since otherwise pages with a very high PageRank would rank high in search results even if the page is not related to the search query.
Especially for queries consisting of two or more search terms, there is a far bigger influence of the content related ranking criteria, whereas the impact of PageRank is mainly visible for unspecific single word queries. If webmasters target search phrases of two or more words it is possible for them to achieve better rankings than pages with high PageRank by means of classical search engine optimisation.
If pages are optimised for highly competitive search terms, it is essential for good rankings to have a high PageRank, even if a page is well optimised in terms of classical search engine optimisation. The reason therefore is that the increase of IR score deminishes the more often the keyword occurs within the document or the anchor texts of inbound links to avoid spam by extensive keyword repetition. Thereby, the potentialities of classical search engine optimisation are limited and PageRank becomes the decisive factor in highly competitive areas.
The PageRank Display of the Google Toolbar
PageRank became widely known by the PageRank display of the Google Toolbar. The Google Toolbar is a browser plug-in for Microsoft Internet Explorer which can be downloaded from the Google web site. The Google Toolbar provides some features for searching Google more comfortably.

The Google Toolbar displays PageRank on a scale from 0 to 10. First of all, the PageRank of an actually visited page can be estimated by the width of the green bar within the display. If the user holds his mouse over the display, the Toolbar also shows the PageRank value.
Caution: The PageRank display is one of the advanced features of the Google Toolbar. And if those advanced features are enabled, Google collects usage data. Additionally, the Toolbar is self-updating and the user is not informed about updates. So, Google has access to the user's hard drive.
If we take into account that PageRank can theoretically have a maximum value of up to dN+(1-d), where N is the total number of web pages and d is usually set to 0.85, PageRank has to be scaled for the display on the Google Toolbar. It is generally assumed that the scalation is not linearly but logarithmically. At a damping factor of 0.85 and, therefore, a minimum PageRank of 0.15 and at an assumed logaritmical basis of 6 we get a scalation as follows:
| Toolbar PageRank | Real PageRank |
|---|
| 0/10 | 0.15 - 0.9 |
| 1/10 | 0.9 - 5.4 |
| 2/10 | 5.4 - 32.4 |
| 3/10 | 32.4 - 194.4 |
| 4/10 | 194.4 - 1,166.4 |
| 5/10 | 1,166.4 - 6,998.4 |
| 6/10 | 6,998.4 - 41,990.4 |
| 7/10 | 41,990.4 - 251,942.4 |
| 8/10 | 251,942.4 - 1,511,654.4 |
| 9/10 | 1,511,654.4 - 9,069,926.4 |
| 10/10 | 9,069,926.4 - 0.85 � N + 0.15 |
It is uncertain if in fact a logarithmical scalation in a strictly mathematical sense takes place. There is likely a manual scalation which follows a logarithmical scheme, so that Google has control over the number of pages within the single Toolbar PageRank ranges. The logarithmical basis for this scheme should be between 6 and 7, which can for instance be rudimentary deduced from the number of inbound links of pages with a high Toolbar PageRank from pages with a Toolbar PageRank higher than 4, which are shown by Googe using the link command.
The Toolbar's PageRank Files
Even webmasters who do not want to use the Google Toolbar or the Internet Explorer permanently for security and privacy concerns have the possibility to check the PageRank values of their pages. Google submits PageRank values in simple text files to the Toolbar. In former times, this happened via XML. The switch to text files occured in August 2002.
The PageRank files can be requested directly from the domain www.google.com. Basically, the URLs for those files look like follows (without line breaks):
https://www.google.com/search?
client=navclient-auto&
ch=0123456789&
features=Rank&
q=info:https://www.domain.com/
There is only one line of text in the PageRank files. The last cipher in this line is PageRank.
The parameters incorporated in the above shown URL are inevitable for the display of the PageRank files in a browser. The value "navclient-auto" for the parameter "client" identifies the Toolbar. Via the parameter "q" the URL is submitted. The value "Rank" for the parameter "features" determines that the PageRank files are requested. If it is omitted, Google's servers still transmit XML files. The parameter "ch" transfers a checksum for the URL to Google, whereby this checksum can only change when the Toolbar version is updated by Google.
Thus, it is necessary to install the Toolbar at least once to find out about the checksum of one's URLs. To track the communication between the Toolbar and Google, often the use of packet sniffers, local proxies an similar tools is suggested. But this is not necessarily needed, since the PageRank files are cached by the Internet Explorer. So, the checksums can simply been found out by having a look at the folder Temporary Internet Files. Knowing the checksums of your URLs, you can view the PageRank files in your browser and you do not have to accept Google's 36 years lasting cookies.
Since the PageRank files are kept in the browser cache and, thus, are clearly visible, and as long as requests are not automated, watching the PageRank files in a browser should not be a violation of Google's Terms of Service. However, you should be cautious. The Toolbar submits its own User-Agent to Google. It is:
Mozilla/4.0 (compatible; GoogleToolbar 1.1.60-deleon; OS SE 4.10)
1.1.60-deleon is a Toolbar version which may of course change. OS is the operating system that you have installed. So, Google is able to identify requests by browsers, if they do not go out via a proxy and if the User-Agent is not modified accordingly.
Taking a look at IE's cache, one will normally notice that the PageRank files are not requested from the domain www.google.com but from IP addresses like 216.239.33.102. Additionally, the PageRank files' URLs often contain a parameter "failedip" that is set to values like "216.239.35.102;1111" (Its function is not absolutely clear). The IP addresses are each related to one of Google's seven data centers and the reason for the Toolbar querying IP-addresses is most likely to control the PageRank display in a better way, especially in times of the "Google Dance".
The PageRank Display at the Google Directory
Webmasters who do not want to check the PageRank files that are used by the toolbar have another possibility to receive information about the PageRank of their sites by means of the Google Directory (directory.google.com).
The Google Directory is a dump of the Open Directory Project (dmoz.org), which shows the PageRank for listed documents similarly to the Google Toolbar display scaled and by means of a green bar. In contrast to the Toolbar, the scale is from 1 to 7. The exact value is not displayed, but it can be determined by the divided bar respectively the width of the single graphics in the source code of the page if one is not sure by looking at the bar.
By comparing the Toolbar PageRank of a document with its Directory PageRank, a more exact estimation of a pages PageRank can be deduced, if the page is listed with the ODP. This connection was mentioned first by Chris Raimondi (www.searchnerd.com/pagerank).

Especially for pages with a Toolbar PageRank of 5 or 6, one can appraise if the page is on the upper or the lower end of its Toolbar scale. It shall be noted that for the comparison the Toolbar PageRank of 0 was not taken into account. It can easily be verified that this is appropriate by looking at pages with a Toolbar PageRank of 3. However, it has to be considered that for a verification pages of the Google Directory respectively the ODP with a Toolbar PageRank of 4 or lower have to be chosen, since otherwise no pages linked from there with a Toolbar PageRank of 3 will be found.
The Effect of Inbound Links
It has already been shown that each additional inbound link for a web page always increases that page's PageRank. Taking a look at the PageRank algorithm, which is given by:
PR(A) = (1-d) + d (PR(T1)/C(T1) + ... + PR(Tn)/C(Tn))
one may assume that an additional inbound link from page X increases the PageRank of page A by:
d � PR(X) / C(X)
where PR(X) is the PageRank of page X and C(X) is the total number of its outbound links. But page A usually links to other pages itself. Thus, these pages get a PageRank benefit also. If these pages link back to page A, page A will have an even higher PageRank benefit from its additional inbound link.
The single effects of additional inbound links shall be illustrated by an example.
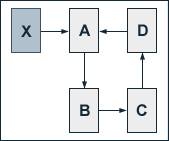
We regard a website consisting of four pages A, B, C and D which are linked to each other in circle. Without external inbound links to one of these pages, each of them obviously has a PageRank of 1. We now add a page X to our example, for which we presume a constant Pagerank PR(X) of 10. Further, page X links to page A by its only outbound link. Setting the damping factor d to 0.5, we get the following equations for the PageRank values of the single pages of our site:
PR(A) = 0.5 + 0.5 (PR(X) + PR(D)) = 5.5 + 0.5 PR(D)
PR(B) = 0.5 + 0.5 PR(A)
PR(C) = 0.5 + 0.5 PR(B)
PR(D) = 0.5 + 0.5 PR(C)
Since the total number of outbound links for each page is one, the outbound links do not need to be considered in the equations. Solving them gives us the following PageRank values:
PR(A) = 19/3 = 6.33
PR(B) = 11/3 = 3.67
PR(C) = 7/3 = 2.33
PR(D) = 5/3 = 1.67
We see that the initial effect of the additional inbound link of page A, which was given by:
d � PR(X) / C(X) = 0,5 � 10 / 1 = 5
is passed on by the links on our site.
The Influence of the Damping Factor
The degree of PageRank propagation from one page to another by a link is primarily determined by the damping factor d. If we set d to 0.75 we get the following equations for our above example:
PR(A) = 0.25 + 0.75 (PR(X) + PR(D)) = 7.75 + 0.75 PR(D)
PR(B) = 0.25 + 0.75 PR(A)
PR(C) = 0.25 + 0.75 PR(B)
PR(D) = 0.25 + 0.75 PR(C)
Solving these equations gives us the following PageRank values:
PR(A) = 419/35 = 11.97
PR(B) = 323/35 = 9.23
PR(C) = 251/35 = 7.17
PR(D) = 197/35 = 5.63
First of all, we see that there is a significantly higher initial effect of additional inbound link for page A which is given by:
d � PR(X) / C(X) = 0.75 � 10 / 1 = 7.5
This initial effect is then propagated even stronger by the links on our site. In this way, the PageRank of page A is almost twice as high at a damping factor of 0.75 than it is at a damping factor of 0.5. At a damping factor of 0.5 the PageRank of page A is almost four times superior to the PageRank of page D, while at a damping factor of 0.75 it is only a little more than twice as high. So, the higher the damping factor, the larger is the effect of an additional inbound link for the PageRank of the page that receives the link and the more evenly distributes PageRank over the other pages of a site.
The Actual Effect of Additional Inbound Links
At a damping factor of 0.5, the accumulated PageRank of all pages of our site is given by:
PR(A) + PR(B) + PR(C) + PR(D) = 14
Hence, by a page with a PageRank of 10 linking to one page of our example site by its only outbound link, the accumulated PageRank of all pages of the site is increased by 10. (Before adding the link, each page has had a PageRank of 1.) At a damping factor of 0.75 the accumulated PageRank of all pages of the site is given by:
PR(A) + PR(B) + PR(C) + PR(D) = 34
This time the accumulated PageRank increases by 30. The accumulated PageRank of all pages of a site always increases by:
(d / (1-d)) � (PR(X) / C(X))
where X is a page additionally linking to one page of the site, PR(X) is its PageRank and C(X) its number of outbound links. The formula presented above is only valid, if the additional link points to a page within a closed system of pages, as, for instance, a website without outbound links to other sites. As far as the website has links pointing to external pages, the surplus for the site itself diminishes accordingly, because a part of the additional PageRank is propagated to external pages.
The justification of the above formula is given by Raph Levien and it is based on the Random Surfer Model. The walk length of the random surfer is an exponential distribution with a mean of (d/(1-d)). When the random surfer follows a link to a closed system of web pages, he visits on average (d/(1-d)) pages within that closed system. So, this much more PageRank of the linking page - weighted by the number of its outbound links - is distributed to the closed system.
For the actual PageRank calculations at Google, Lawrence Page und Sergey Brin claim to usually set the damping factor d to 0.85. Thereby, the boost for a closed system of web pages by an additional link from page X is given by:
(0.85 / 0.15) � (PR(X) / C(X)) = 5.67 � (PR(X) / C(X))
So, inbound links have a far larger effect than one may assume.
The PageRank-1 Rule
Users of the Google Toolbar often notice that pages with a certain Toolbar PageRank have an inbound link from a page with a Toolbar PageRank which is higher by one. Some take this observation to doubt the validity of the PageRank algorithm presented here for the actual ranking methods of the Google search engine. It shall be shown, however, that the PageRank-1 rule complies with the PageRank algorithm.
Basically, the PageRank-1 rule proves the fundamental principle of PageRank. Web pages are important themselves if other important web pages link to them. It is not necessary for a page to have many inbound links to rank well. A single link from a high ranking page is sufficient.
To show the actual consistance of the PageRank-1 rule with the PageRank algorithm several factors have to be taken into consideration. First of all, the toolbar PageRank is a logarithmically scaled version of real PageRank values. If the PageRank value of one page is one higher than the PageRank value of another page in terms of Toolbar PageRank, than its real PageRank can at least be higher by an amount which equals the logarithmical basis for the scalation of Toolbar PageRank. If the logarithmical basis for the scalation is 6 and the toolbar PageRank of a linking Page is 5, then the real PageRank of the page which receives the link can be at least 6 times smaller to make that page still get a toolbar PageRank of 4.
However, the number of outbound links on the linking page thwarts the effect of the logarithmical basis, because the PageRank propagation from one page to another is devided by the number of outbound links on the linking page. But it has already been shown that the PageRank benefit by a link is higher than PageRank algorithm's term d(PR(Ti)/C(Ti)) pretends. The reason is that the PageRank benefit for one page is further distributed to other pages within the site. If those pages link back as it usualy happens, the PageRank benefit for the page which initially received the link is accordingly higher. If we assume that at a high damping factor the logarithmical basis for PageRank scalation is 6 and a page receives a PageRank benefit which is twice as high as the PageRank of the linking page devided by the number of its outbound links, the linking page could have at least 12 outbound links so that the Toolbar PageRank of the page receiving the link is still at most one lower than the toolbar PageRank of the linking page.
A number of 12 outbound links admittedly seems relatively small. But normally, if a page has an external inbound link, this is not the only one for that page. Most likely other pages link to that page and propagate PageRank to it. And if there are examples where a page receives a single link from another page and the PageRanks of both pages comply the PageRank-1 rule although the linking page has many outbound links, this is first of all an indication for the linking page's toolbar PageRank being at the upper end of its scale. The linking page could be a "high" 5 and the page receiving the link could be a "low" 4. In this way, the linking page could have up to 72 outbound links. This number rises accordingly if we assume a higher logarithmical basis for the scalation of Toolbar PageRank.
The Effect of Outbound Links
Since PageRank is based on the linking structure of the whole web, it is inescapable that if the inbound links of a page influence its PageRank, its outbound links do also have some impact. To illustrate the effects of outbound links, we take a look at a simple example.
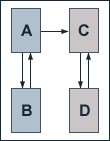
We regard a web consisting of to websites, each having two web pages. One site consists of pages A and B, the other constists of pages C and D. Initially, both pages of each site solely link to each other. It is obvious that each page then has a PageRank of one. Now we add a link which points from page A to page C. At a damping factor of 0.75, we therefore get the following equations for the single pages' PageRank values:
PR(A) = 0.25 + 0.75 PR(B)
PR(B) = 0.25 + 0.375 PR(A)
PR(C) = 0.25 + 0.75 PR(D) + 0.375 PR(A)
PR(D) = 0.25 + 0.75 PR(C)
Solving the equations gives us the following PageRank values for the first site:
PR(A) = 14/23
PR(B) = 11/23
We therefore get an accumulated PageRank of 25/23 for the first site. The PageRank values of the second site are given by:
PR(C) = 35/23
PR(D) = 32/23
So, the accumulated PageRank of the second site is 67/23. The total PageRank for both sites is 92/23 = 4. Hence, adding a link has no effect on the total PageRank of the web. Additionally, the PageRank benefit for one site equals the PageRank loss of the other.
The Actual Effect of Outbound Links
As it has already been shown, the PageRank benefit for a closed system of web pages by an additional inbound link is given by:
(d / (1-d)) � (PR(X) / C(X))
where X is the linking page, PR(X) is its PageRank and C(X) is the number of its outbound links. Hence, this value also represents the PageRank loss of a formerly closed system of web pages, when a page X within this system of pages now points by a link to an external page.
The validity of the above formula requires that the page which receives the link from the formerly closed system of pages does not link back to that system, since it otherwise gains back some of the lost PageRank. Of course, this effect may also occur when not the page that receives the link from the formerly closed system of pages links back directly, but another page which has an inbound link from that page. Indeed, this effect may be disregarded because of the damping factor, if there are enough other web pages in-between the link-recursion. The validity of the formula also requires that the linking site has no other external outbound links. If it has other external outbound links, the loss of PageRank of the regarded site diminishes and the pages already receiving a link from that page lose PageRank accordingly.
Even if the actual PageRank values for the pages of an existing web site were known, it would not be possible to calculate to which extend an added outbound link diminishes the PageRank loss of the site, since the above presented formula regards the status after adding the link.
Intuitive Justification of the Effect of Outbound Links
The intuitive justification for the loss of PageRank by an additional external outbound link according to the Random Surfer Modell is that by adding an external outbound link to one page the surfer will less likely follow an internal link on that page. So, the probability for the surfer reaching other pages within a site diminishes. If those other pages of the site have links back to the page to which the external outbound link has been added, also this page's PageRank will deplete.
We can conclude that external outbound links diminish the totalized PageRank of a site and probably also the PageRank of each single page of a site. But, since links between web sites are the fundament of PageRank and indespensable for its functioning, there is the possibility that outbound links have positive effects within other parts of Google's ranking criteria. Lastly, relevant outbound links do constitute the quality of a web page and a webmaster who points to other pages integrates their content in some way into his own site.
Dangling Links
An important aspect of outbound links is the lack of them on web pages. When a web page has no outbound links, its PageRank cannot be distributed to other pages. Lawrence Page and Sergey Brin characterise links to those pages as dangling links.
The effect of dangling links shall be illustrated by a small example website. We take a look at a site consisting of three pages A, B and C. In our example, the pages A and B link to each other. Additionally, page A links to page C. Page C itself has no outbound links to other pages. At a damping factor of 0.75, we get the following equations for the single pages' PageRank values:
PR(A) = 0.25 + 0.75 PR(B)
PR(B) = 0.25 + 0.375 PR(A)
PR(C) = 0.25 + 0.375 PR(A)
Solving the equations gives us the following PageRank values:
PR(A) = 14/23
PR(B) = 11/23
PR(C) = 11/23
So, the accumulated PageRank of all three pages is 36/23 which is just over half the value that we could have expected if page A had links to one of the other pages. According to Page and Brin, the number of dangling links in Google's index is fairly high. A reason therefore is that many linked pages are not indexed by Google, for example because indexing is disallowed by a robots.txt file. Additionally, Google meanwhile indexes several file types and not HTML only. PDF or Word files do not really have outbound links and, hence, dangling links could have major impacts on PageRank.
In order to prevent PageRank from the negative effects of dangling links, pages wihout outbound links have to be removed from the database until the PageRank values are computed. According to Page and Brin, the number of outbound links on pages with dangling links is thereby normalised. As shown in our illustration, removing one page can cause new dangling links and, hence, removing pages has to be an iterative process. After the PageRank calculation is finished, PageRank can be assigned to the formerly removed pages based on the PageRank algorithm. Therefore, as many iterations are needed as for removing the pages. Regarding our illustration, page C could be processed before page B. At that point, page B has no PageRank yet and, so, page C will not receive any either. Then, page B receives PageRank from page A and during the second iteration, also page C gets its PageRank.
Regarding our example website for dangling links, removing page C from the database results in page A and B each having a PageRank of 1. After the calculations, page C is assigned a PageRank of 0.25 + 0.375 PR(A) = 0.625. So, the accumulated PageRank does not equal the number of pages, but at least all pages which have outbound links are not harmed from the danging links problem.
By removing dangling links from the database, they do not have any negative effects on the PageRank of the rest of the web. Since PDF files are dangling links, links to PDF files do not diminish the PageRank of the linking page or site. So, PDF files can be a good means of search engine optimisation for Google.
The Effect of the Number of Pages
Since the accumulated PageRank of all pages of the web equals the total number of web pages, it follows directly that an additional web page increases the added up PageRank for all pages of the web by one. But far more interesting than the effect on the added up PageRank of the web is the impact of additional pages on the PageRank of actual websites.
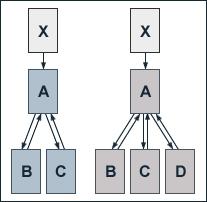
To illustrate the effects of addional web pages, we take a look at a hierachically structured web site consisting of three pages A, B and C, which are joined by an additional page D on the hierarchically lower level of the site. The site has no outbound links. A link from page X which has no other outbound links and a PageRank of 10 points to page A. At a damping factor d of 0.75, the equations for the single pages' PageRank values before adding page D are given by:
PR(A) = 0.25 + 0.75 (10 + PR(B) + PR(C))
PR(B) = PR(C) = 0.25 + 0.75 (PR(A) / 2)
Solving the equations gives us the follwing PageRank values:
PR(A) = 260/14
PR(B) = 101/14
PR(C) = 101/14
After adding page D, the equations for the pages' PageRank values are given by:
PR(A) = 0.25 + 0.75 (10 + PR(B) + PR(C) + PR(D))
PR(B) = PR(C) = PR(D) = 0.25 + 0.75 (PR(A) / 3)
Solving these equations gives us the follwing PageRank values:
PR(A) = 266/14
PR(B) = 70/14
PR(C) = 70/14
PR(D) = 70/14
As to be expected since our example site has no outbound links, after adding page D, the accumulated PageRank of all pages increases by one from 33 to 34. Further, the PageRank of page A rises marginally. In contrast, the PageRank of pages B and C depletes substantially.
The Reduction of PageRank by Additional Pages
By adding pages to a hierarchically structured websites, the consequences for the already existing pages are nonuniform. The consequences for websites with a different structure shall be shown by another example.
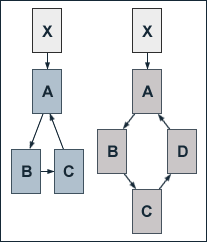
We take a look at a website constisting of three pages A, B and C which are linked to each other in circle. The pages are then joined by page D which fits into the circular linking structure. The regarded site has no outbound links. Again, a link from page X which has no other outbound links and a PageRank of 10 points to page A. At a damping factor d of 0.75, the equations for the single pages' PageRank values before adding page D are given by:
PR(A) = 0.25 + 0.75 (10 + PR(C))
PR(B) = 0.25 + 0.75 � PR(A)
PR(C) = 0.25 + 0.75 � PR(B)
Solving the equations gives us the follwing PageRank values:
PR(A) = 517/37 = 13.97
PR(B) = 397/37 = 10.73
PR(C) = 307/37 = 8.30
After adding page D, the equations for the pages' PageRank values are given by:
PR(A) = 0.25 + 0.75 (10 + PR(D))
PR(B) = 0.25 + 0.75 � PR(A)
PR(C) = 0.25 + 0.75 � PR(B)
PR(D) = 0.25 + 0.75 � PR(C)
Solving these equations gives us the follwing PageRank values:
PR(A) = 419/35 = 11.97
PR(B) = 323/35 = 9.23
PR(C) = 251/35 = 7.17
PR(D) = 197/35 = 5.63
Again, after adding page D, the accumulated PageRank of all pages increases by one from 33 to 34. But now, any of the pages which already existed before page D was added lose PageRank. The more uniform PageRank is distributed by the links within a site, the more likely will this effect occur.
Since adding pages to a site often reduces PageRank for already existing pages, it becomes obvious that the PageRank algorithm tends to privilege smaller web sites. Indeed, bigger web sites can counterbalance this effect by being more attractive for other webmasters to link to them, simply because they have more content.
None the less, it is also possible to increase the PageRank of existing pages by additional pages. Therefore, it has to be considered that as few PageRank as possible is distributed to these additional pages.
Up to this point, it has been described how the number of pages and the number of inbound and outbound links, respectively, influence PageRank. Here, it will mainly be discussed in how far PageRank can be affected for the purpose of search engine optimisation by a website's internal linking structure.
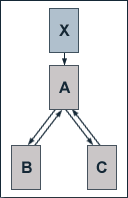
In most cases, websites are hierachically structured to a certain extend, as it is illustrated in our example of a web site consisting of the pages A, B and C. Normally, the root page is withal optimised for the most important search phrase. In our example, the optimised page A has an external inbound link from page X which has no other outbound links and a PageRank of 10. The pages B and C each receive a link from page A and link back to it. If we set the damping factor d to 0.5 the equations for the single pages' PageRank values are given by:
PR(A) = 0.5 + 0.5 (10 + PR(B) + PR (C))
PR(B) = 0.5 + 0.5 (PR(A) / 2)
PR(C) = 0.5 + 0.5 (PR(A) / 2)
Solving the equations gives us the follwing PageRank values:
PR(A) = 8
PR(B) = 2.5
PR(C) = 2.5
It is generally not advisable to solely work on the root page of a site for the purpose of search engine optimisation. Indeed, it is, in most cases, more reasonable to optimise each page of a site for different search phrases.
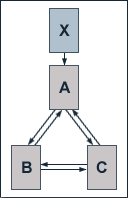
We now assume that the root page of our example website provides satisfactory results for its search phrase, but the other pages of the site do not, and therefore we modify the linking structure of the website. We add links from page B to page C and vice versa to our formerly hierarchically structured example site. Again, page A has an external inbound link from page X which has no other outbound links and a PageRank of 10. At a damping factor d of 0.5, the equations for the single pages' PageRank values are given by:
PR(A) = 0.5 + 0.5 (10 + PR(B) / 2 + PR(C) / 2)
PR(B) = 0.5 + 0.5 (PR(A) / 2 + PR(C) / 2)
PR(C) = 0.5 + 0.5 (PR(A) / 2 + PR(B) / 2)
Solving the equations gives us the follwing PageRank values:
PR(A) = 7
PR(B) = 3
PR(C) = 3
The result of adding internal links is an increase of the PageRank values of pages B and C, so that they likely will rise in search engine result pages for their targeted keywords. On the other hand, of course, page A will likely rank lower because of its diminished PageRank.
Generally spoken, PageRank will distribute for the purpose of search engine optimisation more equally among the pages of a site, the more the hierarchically lower pages are interlinked.
Well Directed PageRank Distribution by Concentration of Outbound Links
It has already been demonstrated that external outbound links tend to have negative effects on the PageRank of a website's web pages. Here, it shall be illustrated how this effect can be reduced for the purpose of search engine optimisation by the systematic arrangement of external outbound links.
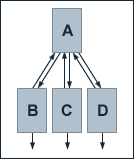
We take a look at another hierarchically structured example site consisting of the pages A, B, C and D. Page A has links to the pages B, C and D. Besides a link back to page A, each of the pages B, C and D has one external outbound link. None of those external pages which receive links from the pages B, C and D link back to our example site. If we assume a damping factor d of 0.5, the equations for the calculation of the single pages' PageRank values are given by:
PR(A) = 0.5 + 0.5 (PR(B) / 2 + PR(C) / 2 + PR(D) / 2)
PR(B) = PR(C) = PR(D) = 0.5 + 0.5 (PR(A) / 3)
Solving the equations gives us the follwing PageRank values:
PR(A) = 1
PR(B) = 2/3
PR(C) = 2/3
PR(D) = 2/3
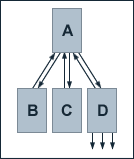
Now, we modify our example site in a way that page D has all three external outbound links while pages B and C have no more external outbound links. Besides this, the general conditions of our example stay the same as above. None of the external pages which receive a link from pages D link back to our example site. If we, again, assume a damping factor d of 0.5, the equations for the calculations of the single pages' PageRank values are given by:
PR(A) = 0.5 + 0.5 (PR(B) + PR(C) + PR(D) / 4)
PR(B) = PR(C) = PR(D) = 0.5 + 0.5 (PR(A) / 3)
Solving these equations gives us the follwing PageRank values:
PR(A) = 17/13
PR(B) = 28/39
PR(C) = 28/39
PR(D) = 28/39
As a result of our modifications, we see that the PageRank values for each single page of our site have increased. Regarding search engine optimisation, it is therefore advisable to concentrate external outbound links on as few pages as possible, as long as it does not lessen a site's usabilty.
Link Exchanges for the purpose of Search Engine Optimisation
For the purpose of search engine optimisation, many webmasters exchange links with others to increase link popularity. As it has already been shown, adding links within closed systems of web pages has no effects on the accumulated PageRank of those pages. So, it is questionable if link exchanges have positive consequences in terms of PageRank at all.
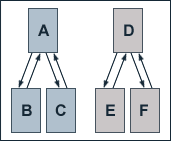
To show the effects of link exchanges, we take a look at an an example of two hierarchically structured websites consisting of pages A, B and C and D, E and F, respectively. Within the first site, page A links to pages B and C and those link back to page A. The second site is structured accordingly, so that the PageRank values for its pages do not have to be computed explicitly. At a damping factor d of 0.5, the equations for the single pages' PageRank values are given by:
PR(A) = 0.5 + 0.5 (PR(B) + PR(C))
PR(B) = PR(C) = 0.5 + 0.5 (PR(A) / 2)
Solving the equations gives us the follwing PageRank values for the first site:
PR(A) = 4/3
PR(B) = 5/6
PR(C) = 5/6
and accordingly for the second site:
PR(D) = 4/3
PR(E) = 5/6
PR(F) = 5/6
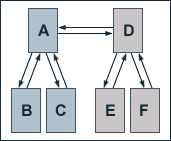
Now, two pages of our example sites start a link exchange. Page A links to page D and vice versa. If we leave the general conditions of our example the same as above and, again, set the damping factor d to 0.5, the equations for the calculations of the single pages' PageRank values are given by:
PR(A) = 0.5 + 0.5 (PR(B) + PR(C) + PR(D) / 3)
PR(B) = PR(C) = 0.5 + 0.5 (PR(A) / 3)
PR(D) = 0.5 + 0.5 (PR(E) + PR(F) + PR(A) / 3)
PR(E) = PR(F) = 0.5 + 0.5 (PR(D) / 3)
Solving these equations gives us the follwing PageRank values:
PR(A) = 3/2
PR(B) = 3/4
PR(C) = 3/4
PR(D) = 3/2
PR(E) = 3/4
PR(F) = 3/4
We see that the link exchange makes pages A and D benefit in terms of PageRank while all other pages lose PageRank. Regarding search engine optimisation, this means that the exactly opposite effect compared to interlinking hierachically lower pages internally takes place. A link exchange is thus advisable, if one page (e.g. the root page of a site) shall be optimised for one important key phrase.
A basic premise for the positive effects of a link exchange is that both involved pages propagate a similar amount of PageRank to each other. If one of the involved pages has a significantly higher PageRank or fewer outbound links, it is likely that all of its site's pages lose PageRank. Here, an important influencing factor is the size of a site. The more pages a web site has, the more PageRank from an inbound link is distributed to other pages of the site, regardless of the number of outbound links on the page that is involved in the link exchange. This way, the page involved in a link exchange itself benefits lesser from the link exchange and cannot propagate as much PageRank to the other page involved in the link exchange. All the influencing factors should be weighted up against each other bevor one trades links.
Finally, it shall be noted that it is possible that all pages of a site benefit from a link exchange in terms of PageRank, whereby also the other site taking part in the link exchange does not lose PageRank. This may occur, when the page involved in the link exchange already has a certain number of external outbound links which don't link back to that site. In this case, less PageRank is lost by the already existing outbound links.
The Yahoo Bonus and its Impact on Search Engine Optimization
Many experts in search engine optimization assume that certain websites obtain a special PageRank evaluation from the Google search engine which needs a manual intervention and does not derive from the PageRank algorithm directly. Mostly, the directories Yahoo and Open Directory Project (dmoz.org) are considered to get this special treatment. In the context of search engine optimization, this assumption would have the consequence that an entry into the above mentioned directories had a big impact on a site's PageRank.
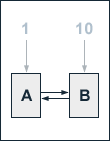
An approach that is often mentioned when talking about influencing the PageRank of certain websites is to assign higher starting values to them before the iterative computation of PageRank begins. Such proceeding shall be reviewed by looking at a simple example web consisting of two pages, whereby each of these pages solely links to the other. We assign an initial PageRank of 10 to one page and a PageRank of 1 to the other. The damping factor d is set to 0.1, because the lower d is, the faster the PageRank values converge during the iterations. So, we get the following equations for the computation of the pages' PageRank values:
PR(A) = 0.9 + 0.1 PR(B)
PR(B) = 0.9 + 0.1 PR(A)
During the iterations, we get the following PageRank values:
| Iteration | PR (A) | PR (B) |
|---|
| 0 | 1 | 10 |
| 1 | 1.9 | 1.09 |
| 2 | 1.009 | 1.0009 |
| 3 | 1.00009 | 1.000009 |
It is obvious that despite assigning different starting values to the two pages each of the PageRank values converges to 1, just as it would have happened if no initial values were assigned. Hence, starting values have no effect on PageRank if a sufficient number of iterations takes place. Indeed, if the computation is performed with only few iterations, the starting values would influence PageRank. But in this case, we have to consider that in our example the PageRank relation between the two pages reverses after the first iteration. However, it shall be noted that for our computation the actual PageRank values within one iteration have been used and not the ones from the previous iteration. If those values would have been used, the PageRank relation had alternated after each iteration.
Modification of the PageRank Algorithm
If assigning special starting values at the begin of the PageRank calculations has no effect on the results of the computation, this does not mean that it is not possible to influence the PageRank of websites or web pages by an intervention in the PageRank algorithm. Lawrence Page, for instance, describes a method for a special evaluation of web pages in his PageRank patent specifications (United States Patent 6,285,999). The starting point for his consideration is that the random surfer of the Random Surfer Model may get bored and stop following links with a constant probabilty, but when he restarts, he won't take a random jump to any page of the web but will rather jump to certain web pages with a higher probability than to others. This behaviour is closer to the behaviour of a real user, who would more likely use, for instance, directories like Yahoo or ODP as a starting point for surfing.
If a special evaluation of certain web pages shall take place, the original PageRank algorithm has to be modified. With another expected value implemented, the algorithm is given as follows:
PR(A) = E(A) (1-d) + d (PR(T1)/C(T1) + ... + PR(Tn)/C(Tn))
Here, (1-d) is the probability for the random surfer no longer following links. E(A) is the probability for the random surfer going to page A after he has stopped following links, weighted by the number of web pages. So, E is another expected value whose average over all pages is 1. In this way, the average of the PageRank values of all pages of the web will continue to converge to 1. Thus, the PageRank values do not vaccilate because of the special evaluation of web pages and the impact of PageRank on the general ranking of web pages remains stable.
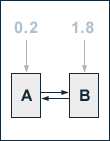
In our example, we set the probability for the random surfer going to page A after he has stopped following links to 0.1. The probability for him going to page B is set to 0.9. Since our web consists of two pages E(A) equals 0.2 and E(B) equals 1.8. At a damping factor d of 0.5 we get the following equations for the calculation of the single pages' PageRank values:
PR(A) = 0.2 � 0.5 + 0.5 � PR(B)
PR(B) = 1.8 � 0.5 + 0.5 � PR(A)
If we solve these equations we get the following PageRank values:
PR(A) = 11/15
PR(B) = 19/15
The sum of the PageRank values remains 2. The higher probability for the random surfer jumping to page B is reflected by its higher PageRank. Indeed, the uniform interlinking between both pages prevents our example pages' PageRank values from a more significant impact of our intervention.
So, it is possible to implement the special evaluation of certain web pages into the PageRank algorithm without having to change it fundamentally. It is questionable, indeed, what criteria is used for the evaluation. Lawrence Page suggests explicitly the utilization of real usage data in his PageRank patent specifications. Google, meanwhile, collects usage date by means of the Google Toolbar. And Google would not even need as much data, as if the whole ranking was solely based on usage data. A limited sample would be sufficient to determine the 1,000 or 10,000 most important pages on the web. The PageRank algorithm can then fill the holes in usage data and is thereby able to deliver a more accurate picture of the web.
Of course, all statements regarding the influence of real usage data on PageRank are pure speculation. Even if there is a special evaluation of certain web pages at all will in the end, stay a secret of the people at Google.
Nonetheless, Assigning Starting Values?
Although, assigning special starting values to pages at the begin of PageRank calculations has no effect on PageRank values it can, nonetheless, be reasonable.
We take a look at our example web constisting of the pages A, B and C, whereby page A links to the pages B and C, page B links to page C and page C links to page A. In this case, the damping factor d is set to 0.75. So, we get the following equations for the iterative computation of the single pages' PageRank values:
PR(A) = 0.25 + 0.75 PR(C)
PR(B) = 0.25 + 0.75 (PR(A) / 2)
PR(C) = 0.25 + 0.75 (PR(A) / 2 + PR(B))
Basically, it is not necessary to assign starting values to the single pages before the computation begins. They simply start with a value of 0 and we get the following PageRank values during the iterations:
| Iteration | PR(A) | PR(B) | PR(C) |
|---|
| 0 | 0 | 0 | 0 |
| 1 | 0.25 | 0.34375 | 0.60156 |
| 2 | 0.70117 | 0.51294 | 0.89764 |
| 3 | 0.92323 | 0.59621 | 1.04337 |
| 4 | 1.03253 | 0.63720 | 1.11510 |
| 5 | 1.08632 | 0.65737 | 1.15040 |
| 6 | 1.11280 | 0.66730 | 1.16777 |
| 7 | 1.12583 | 0.67219 | 1.17633 |
| 8 | 1.13224 | 0.67459 | 1.18054 |
| 9 | 1.13540 | 0.67578 | 1.18261 |
| 10 | 1.13696 | 0.67636 | 1.18363 |
| 11 | 1.13772 | 0.67665 | 1.18413 |
| 12 | 1.13810 | 0.67679 | 1.18438 |
| 13 | 1.13828 | 0.67686 | 1.18450 |
| 14 | 1.13837 | 0.67689 | 1.18456 |
| 15 | 1.13842 | 0.67691 | 1.18459 |
| 16 | 1.13844 | 0.67692 | 1.18460 |
| 17 | 1.13845 | 0.67692 | 1.18461 |
| 18 | 1.13846 | 0.67692 | 1.18461 |
| 19 | 1.13846 | 0.67692 | 1.18461 |
| 20 | 1.13846 | 0.67692 | 1.18461 |
| 21 | 1.13846 | 0.67692 | 1.18461 |
| 22 | 1.13846 | 0.67692 | 1.18462 |
If we assign 1 to each page before the computation starts, we get the following PageRank values during the iterations:
| Iteration | PR(A) | PR(B) | PR(C) |
|---|
| 0 1 1 1 |
| 1 | 1 | 0.625 | 1.09375 |
| 2 | 1.07031 | 0.65137 | 1.13989 |
| 3 | 1.10492 | 0.66434 | 1.16260 |
| 4 | 1.12195 | 0.67073 | 1.17378 |
| 5 | 1.13034 | 0.67388 | 1.17928 |
| 6 | 1.13446 | 0.67542 | 1.18199 |
| 7 | 1.13649 | 0.67618 | 1.18332 |
| 8 | 1.13749 | 0.67656 | 1.18398 |
| 9 | 1.13798 | 0.67674 | 1.18430 |
| 10 | 1.13823 | 0.67684 | 1.18446 |
| 11 | 1.13835 | 0.67688 | 1.18454 |
| 12 | 1.13840 | 0.67690 | 1.18458 |
| 13 | 1.13843 | 0.67691 | 1.18460 |
| 14 | 1.13845 | 0.67692 | 1.18461 |
| 15 | 1.13845 | 0.67692 | 1.18461 |
| 16 | 1.13846 | 0.67692 | 1.18461 |
| 17 | 1.13846 | 0.67692 | 1.18461 |
| 18 | 1.13846 | 0.67692 | 1.18461 |
| 19 | 1.13846 | 0.67692 | 1.18462 |
If we now assign a starting value to each page, which is closer to its effective PageRank (1.1 for page A, 0.7 for page B and 1.2 for page C), we get the following results:
| Iteration | PR(A) | PR(B) | PR(C) |
|---|
| 0 | 1.1 | 0.7 | 1.2 |
| 1 | 1.15 | 0.68125 | 1.19219 |
| 2 | 1.14414 | 0.67905 | 1.18834 |
| 3 | 1.14126 | 0.67797 | 1.18645 |
| 4 | 1.13984 | 0.67744 | 1.18552 |
| 5 | 1.13914 | 0.67718 | 1.18506 |
| 6 | 1.13879 | 0.67705 | 1.18483 |
| 7 | 1.13863 | 0.67698 | 1.18472 |
| 8 | 1.13854 | 0.67695 | 1.18467 |
| 9 | 1.13850 | 0.67694 | 1.18464 |
| 10 | 1.13848 | 0.67693 | 1.18463 |
| 11 | 1.13847 | 0.67693 | 1.18462 |
| 12 | 1.13847 | 0.67692 | 1.18462 |
| 13 | 1.13846 | 0.67692 | 1.18462 |
So, the closer the assigned starting values are to the effective results we would get by solving the equations, the faster do the PageRank values converge in the iterative computation. Less iterations are needed, which can be useful for providing more up to date search results, especially regarding the growth rate of the web. Starting point for an accurate presumption of the actual PageRank distribution may be the PageRank values of a former PageRank calculation. All the pages which are new in the index could get an initial PageRank of 1, which will then be a lot closer to the effective PageRank value after the first few iterations.
It has been widely discussed if additional criteria beyond the link structure of the web have been implemented in the PageRank algorithm since the scientific work on PageRank has been published by Lawrence Page and Sergey Brin. Lawrence Page himself outlines the following potential influencing factors in his patent specifications for PageRank:
- Visibility of a link
- Position of a link within a document
- Distance between web pages
- Importance of a linking page
- Up-to-dateness of a linking page
First of all, the implementation of additional criteria in PageRank would result in a better approximation of human usage regarding the Random Surfer Model. Considering the visibility of a link and its position within a document implies that a user does not click on links completely at haphazard, but rather follows links which are highly and immediately visible regardless of their anchor text. The other criteria would give Google more flexibility in determing in how far an inbound link of a page should be considered important, than the methods which have been described so far.
Whether or not the above mentioned factors are actually implemented in PageRank can not be proved empirically and shall not be discussed here. It shall rather be illustrated in which way additional influencing factors can be implemented in the PageRank algorithm and which options the Google search engine thereby gets in terms of influencing PageRank values.
Modification of the PageRank Algorithm
To implement additional factors in PageRank, the original PageRank algorithm has again to be modified. Since we have to assume that PageRank calculations are still based on numerous iterations and for the purpose of short computation times, we have to consider to keep the number of database queries during the iterations as small as possible. Therefore, the following modification of the PageRank algorithm shall be assumed:
PR(A) = (1-d) + d (PR(T1)�L(T1,A) + ... + PR(Tn)�L(Tn,A))
Here, L(Ti,A) represents the evaluation of a link which points from page Ti to page A. L(Ti,A) withal replaces the PageRank weighting of page Ti by the number of outbound links on page Ti which was given by 1/C(Ti). L(Ti,A) may consist of several factors, each of them having to be determined only once and then being merged to one value before the iterative PageRank calculation begins. So, the number of database queries during the iterations stays the same, although, admittedly, a much larger database has to be queried at each step in comparison to the computation by use of the original algorithm, since now there is an evaluation of each link instead of an evaluation of pages (by the number of their outbound links).
Different Evaluation of Links within a Document
Two of the criteria for the evaluation of links mentioned by Lawrence Page in his PageRank patent specifications are the visibilty of a link and its position within a document. Regarding the Random Surfer Model, those criteria reflect the probability for the random surfer clicking on a link on a specific web page. In the original PageRank algorithm, this probability is given by the term (1/C(Ti)), whereby the probability is equal for each link on one page.
Assigning different probabilities to each link on a page can, for instance, be realized as follows:
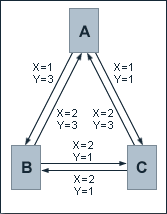
We take a look at a web consisting of three pages A, B anc C, where each of these pages has outbound links to both of the other pages. Links are weighted by two evaluation criteria X and Y. X represents the visibility of a link. X equals 1 if a link is not particularly emphasized, and 2 if the link is, for instance, bold or italic. Y represents the position of a link within a document. Y equals 1 if the link is on the lower half of the page, and 3 if the link is on the upper half of the page. If we assume a multiplicative correlation between X and Y, the links in our example are evaluated as follows:
X(A,B) � Y(A,B) = 1 � 3 = 3
X(A,C) � Y(A,C) = 1 � 1 = 1
X(B,A) � Y(B,A) = 2 � 3 = 6
X(B,C) � Y(B,C) = 2 � 1 = 2
X(C,A) � Y(C,A) = 2 � 3 = 6
X(C,B) � Y(C,B) = 2 � 1 = 2
For the purpose of determinig the single factors L, the evaluated links must not simply be weighted by the number of outbound links on one page, but in fact by the total of evaluated links on the page. Thereby, we get the following weighting quotients Z(Ti) for the single pages Ti:
Z(A) = X(A,B) � Y(A,B) + X(A,C) � Y(A,C) = 4
Z(B) = X(B,A) � Y(B,A) + X(B,C) � Y(B,C) = 8
Z(C) = X(C,A) � Y(C,A) + X(C,B) � Y(C,B) = 8
The evaluation factors L(T1,T2) for a link which is pointing from page T1 to page T2 are hence given by:
L(T1,T2) = X(T1,T2) � Y(T1,T2) / Z(T1)
Their values regarding our example are as follows:
L(A,B) = 0.75
L(A,C) = 0.25
L(B,A) = 0.75
L(B,C) = 0.25
L(C,A) = 0.75
L(C,B) = 0.25
At a damping factor d of 0.5, we get the following equations for the calculation of PageRank values:
PR(A) = 0.5 + 0.5 (0.75 PR(B) + 0.75 PR(C))
PR(B) = 0.5 + 0.5 (0.75 PR(A) + 0.25 PR(C))
PR(C) = 0.5 + 0.5 (0.25 PR(A) + 0.25 PR(B))
Solving these equations gives us the follwing PageRank values for our example:
PR(A) = 819/693
PR(B) = 721/693
PR(C) = 539/693
First of all, we see that page A has the highest PageRank of all three pages. This is caused by page A receiving the relatively higher evaluated link from page B as well as from page C.
Furthermore, we see that even by the evaluation of single links, the sum of the PageRank values of all pages equals 3 (2079/693) and thereby the total number of pages. So, the PageRank values computed by our modified PageRank algorithm can be used for the general ranking of web pages by Google without any normalisation being needed.
Different Evaluation of Links by Page Specific Criteria
Besides the unequal evaluation of links within a document, Lawrence Page mentions the possibility of evaluating links according to criteria which are based upon the linking page. At first glance, this does not seem necessary since it is the main principle of PageRank to rank pages the higher, the more high ranking pages link to them. But, at the time of their scientific work on PageRank, Page and Brin have already recognized that their algorithm is vulnerable to artificial inflation of PageRank.
An artificial influence on PageRank might be exerted by webmasters who generate a multitude of web pages whose links distribute PageRank in a way that single pages within that system receive a special importance. Those pages can have a high PageRank without being linked to from other pages with high PageRank. So, not only the concept of PageRank is undermined, but also the search engine's index is spammed with an innumerable amount of web pages which were solely created to influence PageRank.
In his patent specifications for PageRank, Lawrence Page presents the evaluation of links by the distance between pages as a means to avoid the artificial inflation of PageRank, because the bigger the distance between two pages, the less likely has one webmaster control over both. A criterium for the distance between two pages may be if they are on the same domain or not. In this way, internal links would be weighted less than external links. In the end, any general measure of the distance between links can be used to determine such a weighting. This comprehends if pages are on the same server or not and also the geographical distance between servers.
As another indicator for the importance of a document, Lawrence Page mentions the up-to-dateness of the documents which link to it. This argument considers that the information on a page is less likely outdated, the more pages which have been modified recently link to it. In contrast, the original PageRank concept, just like any method of measuring link popularity, favours older documents which gained their inbound links in the course of their existence and have at a higher probability been modified less recently than new documents. Basically, recently modified documents may be given a higher evaluation by weighting the factor (1-d). In this way, both those recently modified documents and the pages they link to receive a higher PageRank. But, if a page has been modified recently, is not necessarily an indicator for the importance of the information presented on it. So, as suggested by Lawrence Page, it is advisable not to favour recently modified pages but only their outbound links.
Finally, Page mentions the importance of the web location of a page as an indicator of the importance of its outbound links. As an example for an important web location he names the root page of a domain, but, in the end, Google could exert influence on PageRank absolutely arbitrarily.
To implement the evaluation of the linking page into PageRank, the evaluation factor of the modified algorithm must consist of several single factors. For a link that points from page Ti to page A, it can be given as follows:
L(Ti,A) = K(Ti,A) � K1(Ti) � ... � Km(Ti)
where K(Ti,A) is the above presented weighting of a single link within a page by its visibility or position. Additionally, an evaluation of page Ti by m criteria which are represented by the factors Kj(Ti) takes place.
To implement the evaluation of the linking pages, not only the algorithm but also the proceedings of PageRank calculation have to be modified. This shall be illustrated by an example.
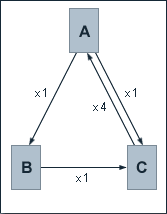
We take a look at a web consisting of three pages A, B and C, whereby page A links to the pages B and C, page B links to page C and page C links to page A. The outbound links of one page are evaluated equally, so there is no weighting by visibilty or position. But now, the pages are evaluated by one criterium. In this way, an inbound link from page C shall be considered four times as important as an inbound link from one of the other pages. After weighting by the number of pages, we get the following evaluation factors:
K(A) = 0.5
K(B) = 0.5
K(C) = 2
At a damping factor d of 0.5, the equations for the computation of the PageRank values are given by:
PR(A) = 0.5 + 0.5 � 2 PR(C)
PR(B) = 0.5 + 0.5 � 0.5 � 0.5 PR(A)
PR(C) = 0.5 + 0.5 (0.5 PR(B) + 0.5 � 0.5 PR(A))
Solving the equations gives us the follwing PageRank values:
PR(A) = 4/3
PR(B) = 2/3
PR(C) = 5/6
At the current modifications of the PageRank algorithm, the accumulated PageRank of all pages no longer equals the number of pages. The reason therefore is that the weighting of the page evaluation by the number of pages was not appropriate. To determine the proper weighting, the web's linking structure would have to be anticipated, which is not possible in case of the actual WWW. Therefore, the PageRank calculated by an evaluation of linking pages has to be normalized if there shall not be any unfounded effects on the general ranking of pages by Google. Within the iterative calculation, a normalization would have to take place after each iteration to minimize unintentional distortions.
In the case of a small web, the evaluation of pages often causes severe distortions. In the case of the actual WWW, these distortions should normally equalise by the number of pages. Indeed, it is to be expected that the evaluation of the distance between pages will cause distortions on PageRank, since pages with many inbound links surely tend to be linked to from different geographical regions. But such effects can be anticipated by experience from previous calculation periods, so that a normalisation would only have to be marginal.
Copyright for this article belongs to pr.efactory.de.